
A General Framework for
Autonomous Animated Agents
James Kuffner, Jr.Stanford CS Robotics Laboratory
August 1999
Overview
The goal of this research is to define a software framework that can facilitate the automatic generation of motion for animated characters at the task-level. Our approach is to view the problem from a robotics perspective, drawing upon the tools and techniques used in the design and control of actual robots. Such tools include algorithms from computational geometry, artificial intelligence, computer vision, and dynamic control systems.
Robotic Systems (Physical Agents)
A robot is essentially a software agent that operates in the physical world. It has control inputs (motors) that apply forces and torques on its joints, which in turn cause the robot to move itself or other objects in it environment. The robot also comes equipped with various kinds of sensors that provide feedback on its motion, along with information about its surroundings. At regular intervals, the robot gathers input from its sensors and formulates a plan of action based upon its current goals and internal state. The plan of action is converted into control inputs, and the cycle repeats.
| This is the control loop of the robot. Given a program of tasks, the robot utilizes the cycle of sensing, planning, and acting, in an effort to accomplish its goals. If the robot has been well-designed and programmed correctly, it will behave intelligently as it goes about performing its tasks. | 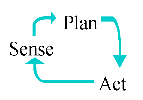 |
The "Virtual Robot" Approach
We consider the problem of creating motion for an animated agent as equivalent to that of building and controlling a virtual robot. Instead of operating in the physical world, an animated agent operates in a virtual world, and employs a "virtual control loop" as follows:
The animated agent has a general set of control inputs which define its motion. These may be values for joint variables that are specified explicitly, or a set of forces and torques that are given as input to a physically-based simulation of the character's body. The animated agent also has a set of "virtual sensors" from which it obtains information about the virtual environment. Based on this information and the agent's current tasks and internal state, appropriate values for its control inputs are computed.
The advantages that a virtual robot has over a physical robot are numerous. While a physical robot must contend with the problems of uncertainty and errors in sensing and control, a virtual robot enjoys "perfect" control and sensing. This means that it should be easier to design an animated agent that behaves intelligently, than a physical agent that does so. In fact, creating an intelligent autonomous animated agent can be viewed as a necessary step along the way towards creating an intelligent autonomous physical robot. If we cannot create a robot that behaves intelligently in simulation, how can we expect to create one in the real world? Thus, adopting a virtual robot approach implies that the scope of this research goes beyond just computer animation, but also extends into the realm of artificial intelligence research.
Building an Animated Agent
Our goal is to create software that will allow an animated character to respond intelligently to task-level commands such as "walk over to the table and pick up the book". These task commands may be given to the character in a number of ways:-
User-specified : task commands generated explicitly by
a user through keystrokes, mouse clicks, voice commands, or
other direct means.
- Software scripts : high-level behavior programs specified via combinations of fundamental programming language constructs, such as if-then-else, while-do, repeat, etc.
- Behavior simulations : software the attempts to model the mental or emotional state of the character, and generates task-level commands based on its internal goals, needs, desires, or preferences. This approach may be considered a special case of a software script approach that employs a detailed model of the character's internal functions or thought processes.
Synthesizing Motion
Generating the underlying motion for an animated character from a set of high-level goals or task commands is not easy. Furthermore, the problem generally rises in difficulty with characters of increasing complexity. Complex characters typically have a large number of animation variables ("avars"), or degrees of freedom (DOF) that must be specified. For example, human characters typically have 15-50 joints arranged hierarchically with anywhere between 40 to 110 degrees of freedom.If every task was very narrowly and explicitly defined, one could imagine simply maintaining a vast library of pre-computed, captured, or hand-animated motions to accomplish every possible task. The reality is that, in general, tasks cannot be so narrowly defined, lest the set of possible tasks become infinite. Instead, tasks are specified at a high-level, and apply to a general class of situations (e.g. "walk to the kitchen", "open the refrigerator", "take out the milk", "pour a glass", "sit down at the table", "take a drink", "wave hello to Mr. Smith", etc.)
|
We propose a motion synthesis strategy that draws upon a collection of
fundamental software components and data libraries. These include a
simulated sensing module, a physically-based simulation module, a
large library of "canned motions", and a library of motion planning
and geometric algorithms. Other potential fundamental component
modules might include numerical optimization libraries, or collections
of biomechanical or neurophysiological data appropriate to specific
classes of character morphology (i.e. humans, dogs, birds,
etc).
A block diagram of the proposed strategy is depicted in the figure to the right. A set of high-level goals are generated and passed to the motion synthesis software. Utilizing some or all of the fundamental software components and data libraries, the resulting motion for the character is computed and passed to the graphic display device for rendering. |
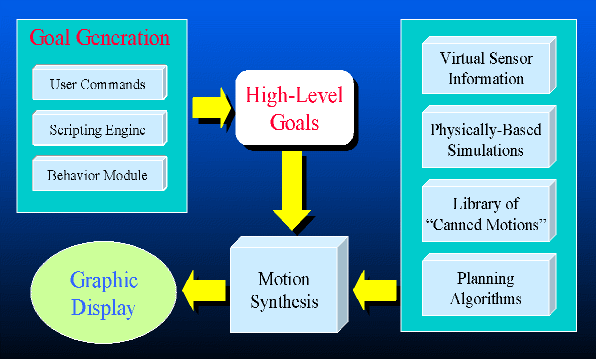
Motion Synthesis Framework (click for a larger image) |
The following sections describe each of the fundamental software components identified above, and briefly indicates how they might be utilized for synthesizing motion. We believe that no single component can provide a general solution to the motion synthesis problem, but rather each technique in combination with one or more of the others may provide a viable approach to generating animation for a given set of tasks.
Clip Motion Libraries
Clip motions ("canned motions") are short animations that have been either keyframed, pre-generated, or obtained via motion capture systems. Such motions can be stored and played back very efficiently. Motion capture data is recorded directly from a live subject and then applied to a character for the purposes of animation. Captured motions are often preferred due to their high level of visual realism. This is especially true of motions involving "dynamic" activities such as walking, running, dancing, or athletic maneuvers. By "dynamic", we mean that the dynamics of the underlying physical system (e.g. the human body) plays a significant role in the overall quality of the motion.
Large libraries of clip motions can potentially become a powerful
resource for animation. Animating a character in a given situation
might ultimately involve selecting a pre-recorded motion from a vast
dictionary indexed by task or motion characteristics. For example,
there may be hundreds of walking motions stored, from among which a
character might utilize a
The primary drawback to clip motions is that any given data set can
usually only be used in a very specific set of situations. For
example, consider a captured motion of a human character opening a
refrigerator and taking out a carton of milk. The motion will only
appear perfect if the virtual model of the character, the
refrigerator, the carton, and their relative positions match the
actual objects used when the motion was captured. What happens if the
carton is placed on the lower shelf instead of the upper shelf? What
if the refrigerator model is made larger, or the location of the
handle on the refrigerator door changes? What happens if a bottle of
orange juice is placed in front of the milk carton? Motion warping,
interpolation, or spacetime constraint techniques exist that attempt
to adapt clip motions to a broader class of situations while enforcing
kinematic and/or dynamic constraints. However, larger deviations can
often cause such adapted motions to lose their visual realism, and
hence their aesthetic quality. Despite these drawbacks, clip motions
will continue to play in important role in real-time animation systems
due to their efficiency and visual realism.
The primary challenge when using motion planning to generate motion is
to achieve visual realism. Aesthetics of motion are of little concern
for robots, but are vitally important for animated characters. The
computed motion must look natural and realistic. It may be possible
to encode aesthetics as search criteria to use during planning, or to
perform post-processing on the planned motion. For example, the
naturalness and realism of a planned motion could arise from an
underlying physically-based model that guides the search.
Alternatively, search criteria might be ultimately derived from clip
motion libraries that represent a particular "style" of motion. Many
possibilities exist, but clearly motion planning is not useful for
tasks where few obstacles to motion exist and/or aesthetics are
extremely important (e.g. facial animation).
Sensory information can be encoded at both a low level and a high
level and utilized by high-level decision-making processes of the
animated agent. Examples of sensory encodings include "all objects
that are currently visible", "all other characters that are currently
nearby", or "sounds that can be currently heard". Because animated
agents operate in virtual environments, they can avoid many of the
problems that physical agents (robots) have when dealing with sensory
information (e.g. noisy data, conflicting data, etc.) Thus, it should
be much easier to build an intelligent virtual robot as opposed
to an intelligent physical robot. In any case, incorporating
some kind of sensory feedback will be necessary to achieve believable
behavior.
Animation generated using physically-based models (dynamic simulation)
has the advantage of exhibiting a very high level of realism.
However, since the underlying motion is dictated by physics, it is
difficult to control the simulation at a task-level. Spacetime
constraint optimization techniques can alleviate some of these
difficulties, but at a computational cost that is largely prohibitive
for real-time animation systems.
Physically-based techniques are very well-suited for generating
non-intentional (secondary) motions. Examples include the
animation of hair, clothing, wind, water, smoke, fire, or falling
objects. However, it is more difficult to apply such techniques to
the animation of intentional (primary) motions, using a
physically-based model of a character. Fundamentally, the key
difficulty lies in computing the required controls necessary to
achieve a particular task. However, this may be another area in which
libraries of captured motions might be useful. One can envision using
the "inverse dynamics" of a given physically-based model in order to
compute the set of controls necessary to achieve a particular captured
motion. Ultimately, libraries of "canned motions" may
eventually be replaced by libraries of "canned sets of
controls" that can be used in combination with a physically-based
model of a character.
Clearly, as the computational resources available to desktop systems
grows, increasingly sophisticated physically-based models can be used
in a variety of ways in order to generate increasingly realistic
animations.
Motion Planning
Motion planning algorithms were initially developed in the context of
robotic systems. Such algorithms generate motion given a high-level
goal and a geometric description of the objects involved. In the
context of computer animation, motion planning can be used to compute
collision-free motions to accomplish high-level navigation or object
manipulation tasks. Motion planning is particularly suited to such
tasks, since there is a near infinite number of possible goal
locations and obstacle arrangements in the environment. Flexible and
efficient algorithms can be designed to compute collision-free motions
towards a given goal location.
Simulated Sensing
Creating an autonomous animated agent with believable behavior in an
interactive virtual environment will ultimately require some kind of
simulated sensing. This can include one or more of simulated visual,
aural, olfactory, or tactile sensing. The basic idea is to more
realistically model the flow of information from the virtual
environment to the character. The character should act and react
according to what it perceives.
Physically-Based Simulation
All motions in the physical world are driven by the laws of physics.
Motions in virtual worlds typically aspire to give the appearance that
they are also driven by the laws of physics. Graphical models
simulate the visual appearance of objects, while physical models
simulate their behavior in the physical world.