
Simulated Sensing for
Autonomous Animated Characters
James Kuffner, Jr.Stanford CS Robotics Laboratory
August 1999
Overview
In order to more realistically model the flow of information from the virtual environment to the character, many researchers have advocated some kind of simulated sensing. This can include one or more of simulated visual, aural, olfactory, or tactile sensing.Synthetic Vision
Simulated visual perception, also known as synthetic vision or animat vision, can provide a powerful means for the character to react based on what it perceives.Determining what is visible to a character can be viewed as one instance of computing a 3D visibility set. Typically, the character has a limited field of view, and possibly a limited range of vision. Thus, computing the visibility set from a character's current location might involve intersecting all environment geometry with the character's cone of vision and performing hidden-surface removal to determine which objects are visible.
A Simple and Fast Synthetic Vision Model
One can avoid expensive intersection and visibility tests by exploiting the Z-buffer found in most graphics rendering hardware. The scene is simply rendered offscreen from the character's point of view, generating an image of what is currently visible to the character. In order to be able to determine exactly which objects are visible, the environment is divided into a set of reasonably-sized objects. Then, each object is assigned an unique ID, which is used as the color of the object for the visibility renderer. The pixels of the rendered image are scanned and a set a currently visible objects is compiled by indexing the pixel color values. Note that the clipping planes can be set appropriately to simulate any limitations on the visual range.

Normal vs. False-color visibility image |

Normal vs. False-color visibility image |
character view frustum |
Spatial Memory Models
The output of the synthetic vision module is a set V of currently visible objects. Each character maintains a set M of observations of particular objects at specific locations and specific times (the character's spatial memory). At regular intervals, M is updated with new observations derived from V according to a set of memory update rules. The updated set M is used as the basis for planning a path given a navigational goal. In this way, the character bases its plans on its own internal model of the world, and updates the model as it senses new information. This is in essence the "sense-plan-act" loop of our proposed "virtual robot" approach:
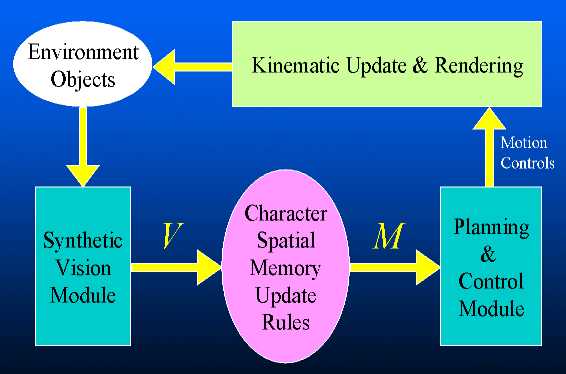
The "virtual control loop" of an animated agent |
The diagram below on the left illustrates how M is
incrementally updated as previously unknown objects are observed. The
diagram on the right illustrates two cases encountered when dealing
with dynamic environments.
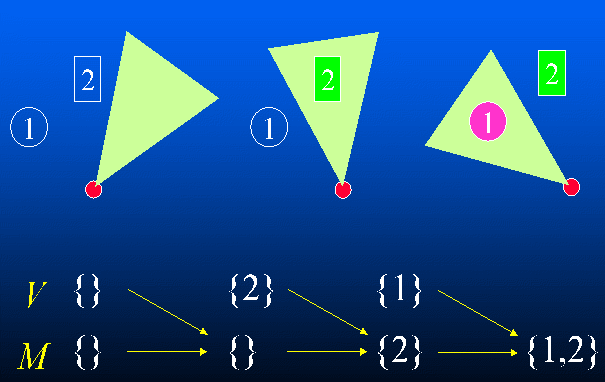
Exploring an unknown static environment |
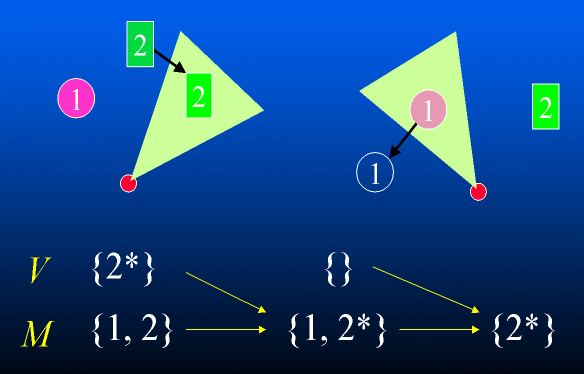
Exploring an unknown dynamic environment |
The problem with dynamic environments lies in recognizing when a
previously observed object has disappeared (or moved) from its
previously observed location. As an example, let us consider the each
of the two illustrated dynamic environment cases in turn:
- A character observes object 2 at some location. Later, object 2 moves to a new location, and is again observed. In this case, the state information for object 2 in M should be simply updated to reflect the new location(2*).
- A character observes object 1 at some location. Later, object 1 moves to a new location. However, before the new location is observed, the character observes its former location (object 1 is now missing). In this case, the previous observation of object 1 in M should be deleted or invalidated.
In order to handle dynamic environments, the character needs to know when to invalidate observations in M. This is done by reinvoking the synthetic vision module using M as the input. This computes Vm, the set of all objects that the character expects to see based on its current internal model of the environment. If the sets V and Vm differ, then we can conclude that one or more observations in M should be invalidated. An updated world model M* is computed and sent to the navigation planning and control module.
Below is the revised sensing loop that is necessary to correctly handle environments in which objects can move, appear, or disappear unpredictably:
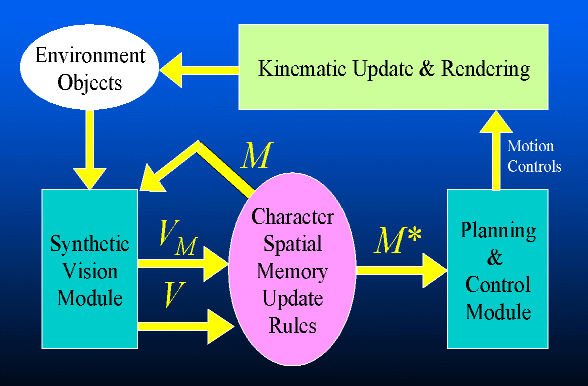
Revised "virtual control loop" for dynamic environments |
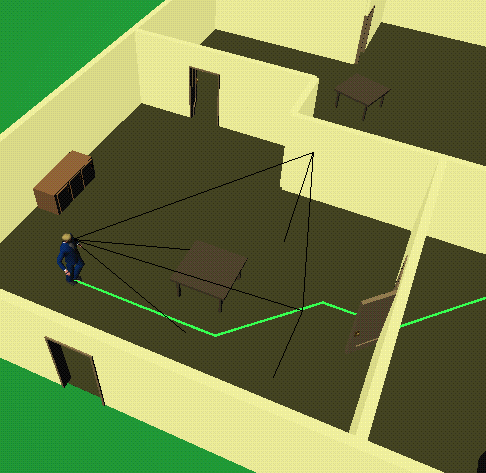
Below are some computed examples involving a human character
navigating an a room of objects that the user can interact with via
the mouse.

A path is computed to the goal based |

When the table is moved behind the |

The table's former location is evident |

Finally, the character turns around and |
Perception-Based Navigation
Using the simple memory update rules outlined above, a character can be made to explore unknown dynamic environments in real-time.Below are two examples involving navigating in unknown maze environments. Both examples show the final trajectory resulting from exploring each maze assuming that nothing was initially known except the location of the navigational goal. In the example on the right, all of the complex backtracking maneuvers resulted directly from the sensing, planning, and memory update rules.

Exploring an unknown maze environment |
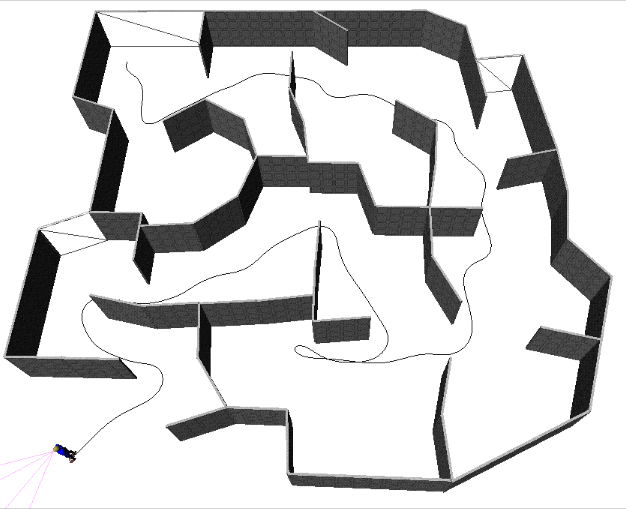
An unknown maze requiring backtracking |
Perception-Based Grasping and Manipulation
The synthetic vision module can be used not only for tasks involving navigation, but for a variety of tasks that require visual coordination. This includes grasping and manipulation tasks (for an overview, see Object Grasping and Manipulation).In the examples below, the synthetic vision module is used in order to verify that a particular target object is visible prior to attempting to grasp it. If the object is visible, the grasping and manipulation planner is invoked. If the target object is not visible, the character will attempt to reposition itself, or initiate a searching behavior in an attempt to find the missing object.

Grasping a coffee pot |

Character view |

Grasping a flashlight |
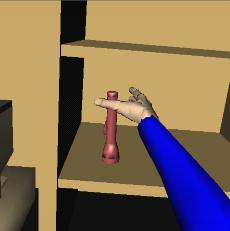
Character view |